The more I try to get it right, the more problems start to appear. I’m talking about making PHP Markdown work with WordPress. It works since a year now, but there have always been many glitches. All this relates to the text flow model WordPress has adopted, which is very powerful but badly adapted to a writing syntax different from HTML.
To work correctly, the Markdown plugin must in some way mess with the inner working of WordPress by moving many filters out the way. Here is some documentation I wrote before losing track of everything.
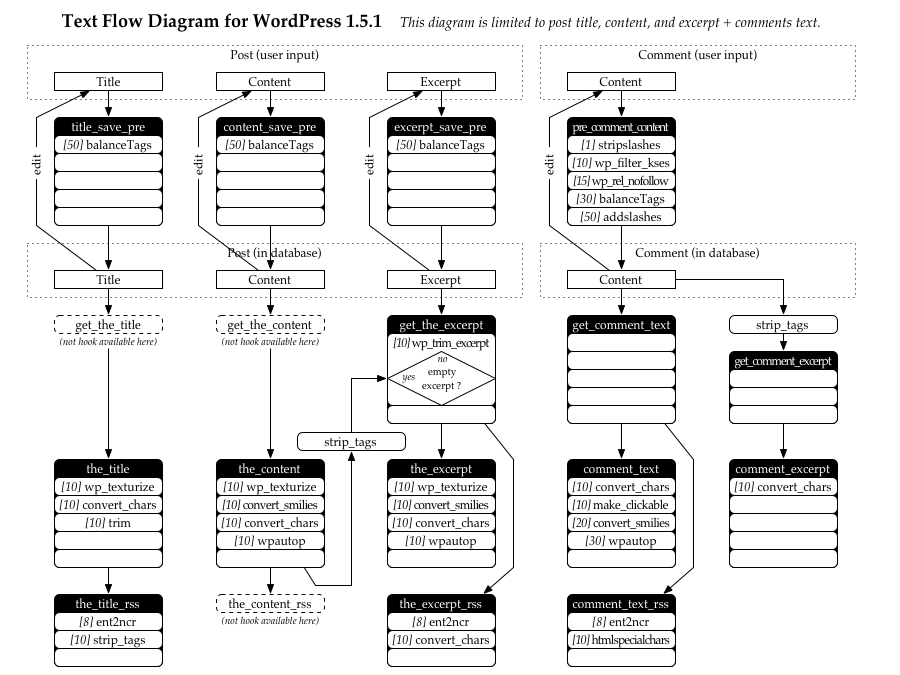
Default Text Flow
Text coming from different places in WordPress pass through a cascade of filters before being displayed. At most places, there are hooks allowing a plugin to insert its own filters. A plugin can also remove filters hooked at these places.
To understand how the text flows inside WordPress, I had to follow it by reading the code. I then made a diagram to keep track of everything. To understand what follows, be sure to look at the PNG diagram or PDF diagram.
I think I found many incoherences:
- At some places, hooks are available when at other similar
places they are not.
- Text going out of
the_title_rss pass through the the_title,
but it does not work the same for the_excerpt_rss and
the_comment_rss.
- When there is no post excerpt, the excerpts is created from the
post’s content after it has passed through filters in
the_content hook. But comment excerpts are made directly from the
database.
Not every of these cause problems to Markdown, but some do, as we will see later.
Performance, Database Storage, Editing, and the balanceTags Filter
The first issue involves all of this. So let’s explain first how things work without Markdown. (Try to follow on the diagram, things should be clearer.) When you create or edit your post, the content pass through the content_save_pre hook which contains the balanceTags filter. This filter balance the tags or, in other words, make sure your XHTML is well formed. Then it saves the content in the database.
This is very important; it means XHTML tags are “corrected” before saving content to the database. After that, if you edit again your post, any correction balanceTags made before will be visible. What you edit again is not exactly what you wrote before.
This may not be an inconvenance if you write in XHTML. But if you write in Markdown, it is.
First thing to note is that the Markdown text filter must absolutely run before balanceTags. Markdown text is not HTML and has many constructs that will be seen as tags by balanceTags. But since Markdown text can include HTML markup, balanceTags is still useful, as long as it runs after Markdown.
Second thing is that if the user goes back to edit the text he wrote, he expect to edit what he wrote, not an XHTML translation of his Markdown text.
This means that Markdown and balanceTags filters cannot run prior saving in the database. They must run after, at page rendering time. Each time a visitor hit your site, the syntax is converted again from Markdown to HTML. For most sites, it’s not that big of an issue, but for the most visited ones, it can be.
(Note: Without Markdown, WordPress still converts paragraphs, smart quotes, and smilies at each page view. It matters a little less because these filters are much simpler and faster than PHP Markdown, but it’s still inefficient.)
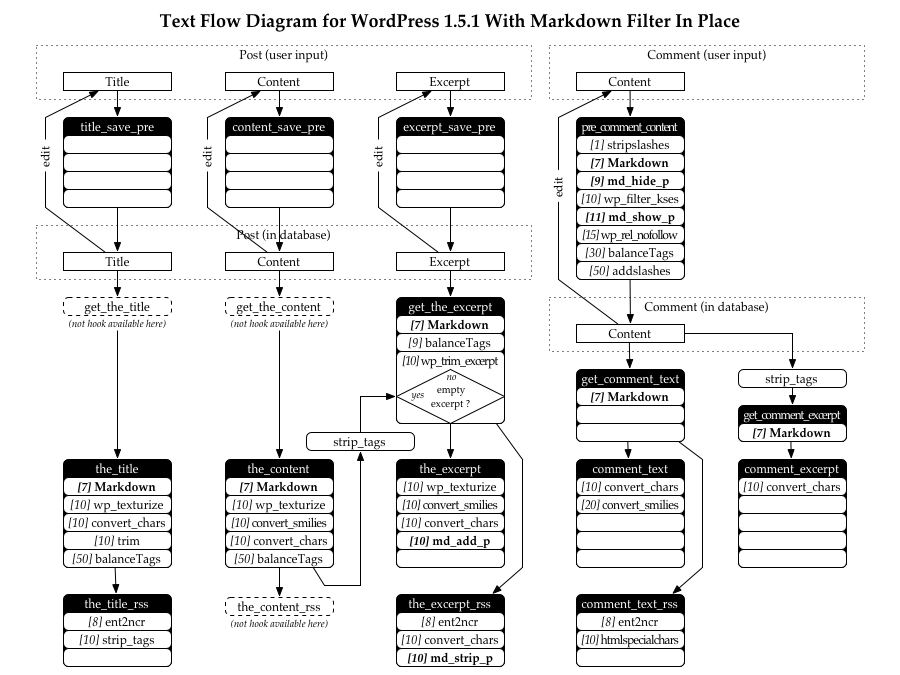
So when Markdown loads it has to do this:
- Remove the
wpautop filter, since Markdown takes care of
paragraphs by itself.
- Install the
Markdown filter at level 7 in the_content,
the_excerpt, and the_excerpt_rss.
- Move
balanceTags from content_save_pre and
excerpt_save_pre so it runs after the Markdown filter in
the_content, the_excerpt, and the_excerpt_rss.
Excerpts Issues
What I wrote above is what PHP Markdown does currently, but this has a flaw. Markdown text is processed twice when the excerpt is generated automatically from the post. In most cases this won’t be an issue. But Markdown allow you to escape certain characters — like *, which means emphasis — to be taken literally. So let’s say someone write this in a post:
This *is* a sentence with literal *asterisks*.
After Markdown filter in the_content hook, it will look like this:
<p>This <em>is</em> a sentence with literal *asterisks*.</p>
When excerpt field in the database is empty, wp_trim_excerpt will strip tags from the_content giving this:
This is a sentence with literal *asterisks*.
And after the_excerpt (or the_excerpt_rss) which include Markdown will do this:
This is a sentence with literal <em>asterisks</em>.
… which is not the desired result. (Note: If there was no tag stripping between the two passes of Markdown, this wouldn’t be an issue because the Markdown syntax is not applied incide block-level tags like <p>)
Another issue is the_excerpt_rss hook. Without Markdown, text coming out of it isn’t surrounded by <p> tags, so it makes sense that Markdown does not do it either.
Here are the solutions to these problems I will include in the next version of PHP Markdown:
- Move the Markdown filter up in the chain before the
wp_trim_excerpt filter.
- Install a custom paragraph filter in
the_excerpt so that
text is wrapped inside a paragraph. It has to be custom because
wpautop creates <br /> tags using different rules than
Markdown.
- Strip paragraph tags produced by Markdown in
the_excerpt_rss.
Comments
What I said up until now applies to posts; comments are another matter with its own problems. As you can see in the diagram, five filters are applied prior saving a comment to the database. In the pre_comment_content hook, wp_filter_kses removes unwanted tags in comments, wp_rel_nofollow adds the rel="nofollow" attribute to links, and balanceTags make sure XHTML content is well-formed. (Don’t ask me what stripslashes and addslashes try to accomplish, I have no idea.)
Since those who post the comments will not have the possibility of editing them again, it would make sense to apply Markdown prior saving to the database. Unfortunately, versions of WordPress prior 1.5 did not allow this, which means that comments currently the database of installed web sites have been saved in Markdown format. So, for backward compatibility, Markdown must be applied at display time.
Since Markdown does not run prior saving to database, other filters which depends on the comment to be HTML (wp_filter_kses, wp_rel_nofollow, and balanceTags) need run at display time too. This is what PHP Markdown 1.0.1a does. But this breaks other plugins… Some plugins want to remove the wp_rel_nofollow filter. Since Markdown moved it elsewhere, they can’t remove it anymore, at least not where they expect to.
So the next version of PHP Markdown will handle things differently. Markdown will be filtered when saving the comment to database, then the comment will be Markdown-filtered again when displaying the page; this will make sure older comments saved in Markdown format are converted to HTML too. This will work because the Markdown syntax has the particularity of leaving HTML blocks alone, which means that a second filter pass won’t do any damage.
Undesirable Tags in Comments
Markdown syntax empowers the user by always giving him the choice between its syntax constructs or HTML. This means that, just like without Markdown, the user can write HTML in the comment field. But it would be dangerous to let visitors write any kind of HTML inside a comment.
I talked in the previous section about the wp_filter_kses filter that filter these undesirable tags. It turns out there is yet another issue, and it revolves around this filter. Without Markdown, wp_filter_kses removes <p> tags, which is not allowed in the comment form but is added later with wpautop (at display time in the comment_text hook); wp_filter_kses also removes <pre> tags.
This poses a problem to Markdown. As I said previously Markdown must run prior wp_filter_kses and other filters that expect input as HTML. But at the same time Markdown should create paragraphs and code blocks after wp_filter_kses has run. In other words, wp_filter_kses should run somewhere inside Markdown, but even this would be difficult without big changes to the order things are processed inside Markdown.
The only satisfactory solution I’ve found is to add two filters around wp_filter_kses, the first one replace <p> and <pre> tags with something wp_filter_kses won’t see as a tag. Then, after wp_filter_kses, the second filter change them back to real tags. This is what I intend to do for the next version of PHP Markdown.
Comment Excerpts
Comment excerpts are relatively new to me, but I can see a problem with them too. As you can see on the diagram, WordPress takes the content of the database, strip the tags, then filter the result using get_comment_excerpt. If the content of the database was not in HTML format, but in Markdown, stripping what look like tags will often have undesired effects.
Parsing comments when they are saved in the database as suggested in the last section will solve this problem for new comments. But excerpts of older comments saved in Markdown format may suffer from the premature tag stripping. Nothing can be done about this with the current text flow structure of WordPress.
Conclusion
To see how Markdown changed the normal text flow, here is a PNG diagram with Markdown or a PDF diagram with Markdown. Compare it with the previous diagram without Markdown. [Update: The text flow diagram with Markdown has been updated now that PHP Markdown 1.0.1b is out.]
When all implemented, this will solve most problems regarding how Markdown integrates with WordPress, for now. I hope new versions of WordPress won’t require more workarounds. I think it’s a shame that it’s so difficult to install an alternate syntax into this thing.
Problems I solved here are not only problems WordPress has with Markdown. For example, if you use the Textile plugin, you can get bad results sometimes (it isn’t as bad since Textile does not use angle brakets much). I didn’t test it, but by looking at the code I think even the excellent TextControl plugin doesn’t get things right.
I hope this text will help some people improving their plugins. I hope it will help explaining what’s wrong to those who want to improve WordPress text filters. But at least, now I’ve documented my little research and can start implementing the working solution.
Supplement: Test Cases
Here is a test case that is hard to get right with WordPress using the Markdown plugin:
This is a `code sample with some <html>`.
And now a code block:
This is a code block with some <html>.
This is an automatic link:
<https://michelf.ca/>
Should be rendered like this by Markdown:
<p>This is a <code>code sample with some <html></code>.
And now a code block:</p>
<pre><code>This is a code block with some <html>.
</pre></code>
<p>This is an automatic link:
<a href="https://michelf.ca/">https://michelf.ca/</a></p>
Here is the same kind of test using Textile here:
<code>sample <html> code</code>
<pre><code>
sample <html> code
</code></pre>
Code will be entity-encoded automaticaly in the output, like this:
<code>sample <html> code</code>
<pre><code>
sample <html> code
</code></pre>
But try to make it work with the Textile WordPress plugin in post, post excerpts, and comments… It won’t.
{kind=link}
{kind=link}